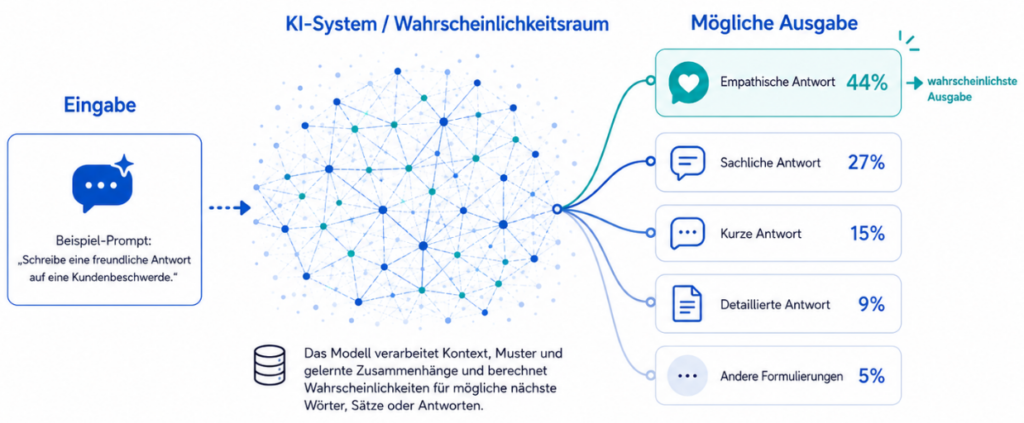
AI Evals: Fünf Dimensionen für produktive KI-Systeme
Im laufenden Betrieb Ihres KI-Systems fallen Ihnen drei Dinge auf. Der Token-Verbrauch steigt von einem Sprint zum nächsten um 40 %, ohne dass eine Konfigurationsänderung das erklären würde. Nach einem Prompt-Update verändert sich die Antwortqualität spürbar; das Team empfindet sie als schlechter, kann aber nicht benennen, warum. Und Ihr RAG-System liefert Aussagen, die in keinem der hinterlegten Dokumente stehen, obwohl die Wissensdatenbank die vereinbarte Quelle ist. Drei verschiedene Symptome, die auf dieselbe Lücke zurückgehen: Niemand misst systematisch, was das System tatsächlich tut.
Was Accuracy verschweigt
Accuracy misst, ob eine Antwort inhaltlich stimmt. Sie sagt nichts darüber, ob der Nutzer nach dem Gespräch weiterkommt, ob das System höflich bleibt, wenn jemand frustriert ist, ob der Retrieval-Schritt die richtigen Dokumente findet, oder ob das System eine Antwort bewusst verweigert, wenn die nötigen Informationen fehlen. Das sind fünf verschiedene Fragen, Accuracy beantwortet davon eine.
In produktiven KI-Systemen laufen Prompts, Modelle, Retrieval-Konfigurationen und Embeddings parallel und verändern sich laufend. Jede Anpassung verändert das Systemverhalten, manchmal subtil, manchmal grundlegend. Ein Finanzdienstleister optimierte sein Retrieval für komplexe Investmentfragen und übersah dabei, dass Compliance-Antworten plötzlich 30 % häufiger unvollständig wurden. Der Fehler fiel erst auf, als ein Auditor nachfragte.
Wann reicht ein einzelner Score nicht mehr aus?
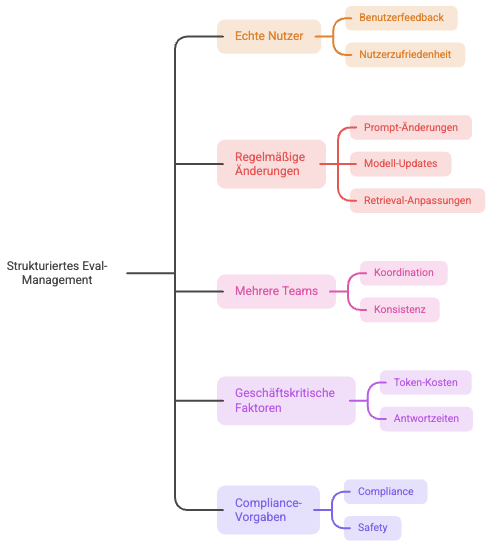
Er reicht nicht mehr aus, sobald mehr als eine Person am System arbeitet oder das System in Produktion läuft. Fünf Situationen machen strukturiertes Eval-Management notwendig:
Das System hat echte Nutzer.
Prompts, Modelle oder Retrieval werden regelmäßig geändert.
Mehrere Teams arbeiten koordiniert am System.
Token-Kosten oder Antwortzeiten sind geschäftskritisch.
Compliance- oder Safety-Vorgaben gelten.
Wer drei oder mehr davon bejaht, betreibt bereits ein System, das strukturiertes Qualitätsmanagement braucht.
Wie misst man KI-Qualität?
Nicht jede Dimension ist für jeden Use Case gleich kritisch. Wer ein System gerade in Produktion bringt, misst nicht alles gleichzeitig, sondern fängt dort an, wo Fehler die größten Konsequenzen haben.
Eine Orientierung: RAG-Systeme beginnen eher bei Grounding, Agentensysteme bei Tooling, Kundenkontakt-Systeme bei Conversation. Alle anderen Dimensionen laufen mit, aber die Startpriorität bestimmt, wo der erste blinde Fleck liegt.
Jetzt Whitepaper herunterladen
Wie systematische AI-Evaluations Ihnen volle Kontrolle und Erfolg sichern.
Wer eine Wissensdatenbank als Quelle festgelegt hat, muss messen, ob das System sich daran hält.
Groundedness prüft, ob Antworten durch abgerufene Quellen gedeckt sind. Das ist der Fehlermodus aus dem Einstieg: ein RAG-System, das anfängt, aus dem Modellwissen statt aus der Wissensdatenbank zu antworten. Der Drift passiert schleichend und fällt ohne Messung erst auf, wenn ein Nutzer eine Aussage nicht mehr nachvollziehen kann.
Citations prüft, ob Quellen korrekt referenziert werden. Bei einem Compliance-System ist das keine akademische Frage: Wenn eine Antwort auf einem seit sechs Monaten überholten Dokument basiert, muss das nachvollziehbar sein.
No-Answer prüft, ob das System bewusst schweigt, wenn Informationen fehlen. Ein System, das bei unbekannten Sachverhalten trotzdem antwortet, birgt das größere Risiko.
Grounding ist auch für Agenten- und Conversation-Systeme relevant, für RAG ist es aber der erste Hebel.
Agent & Tooling: Die Basis für Agentensysteme
Bei Agentensystemen zählt nicht nur das Ergebnis, sondern jeder Schritt dahin.
Tool Selection prüft, ob das System das richtige Werkzeug wählt. Ein Vertriebsagent, der für Preisabfragen das CRM nutzen soll, stattdessen aber eine generische Suche auslöst, liefert Angebote mit Standardwerten statt echten Kundendaten. Klingt plausibel, ist aber falsch.
Tool Execution prüft, ob Parameter korrekt gesetzt und Fehler sauber behandelt werden. Ein falsch befüllter API-Parameter in Schritt zwei eines fünfstufigen Prozesses ist ohne End-to-End-Tracing kaum zu lokalisieren.
Multi-Step Reliability prüft, ob mehrstufige Abläufe stabil laufen. Einzelne Schritte können korrekt funktionieren, während der Gesamtprozess trotzdem scheitert.
Tooling-Metriken sind auch für RAG-Systeme mit Tool-Anbindung relevant. Für reine Agentensysteme sind sie der kritischste Einstiegspunkt.
Conversation: Die Basis für Kundenkontakt-Systeme
Tonalität und Empathie entscheiden in Kundenkontexten darüber, ob Nutzer das System akzeptieren. Ein System, das auf eine zweite, frustrierte Nachricht mit derselben Standardantwort reagiert wie auf die erste, verliert Nutzer. Nicht wegen falscher Fakten, sondern weil es das Gespräch nicht liest.
Policy & Safety prüft, ob das System definierte Richtlinien konsistent einhält. In regulierten Branchen reicht „funktioniert meistens“ nicht. Policykonformität muss reproduzierbar messbar sein.
Conversation-Metriken sind für interne Systeme weniger kritisch als für externe. Für Kundenkontakt-Systeme sind sie der erste blinde Fleck.
Antwort & Outcome: Für alle Systeme ab Tag eins
Diese Dimension gilt unabhängig vom System-Typ. Sie prüft, ob das System seinen eigentlichen Zweck erfüllt.
Task Success fragt, ob das Nutzerziel erreicht wird. Ein Mitarbeiter fragt das interne Wissenssystem nach dem Prozess für Lieferantenfreigaben. Das System antwortet korrekt über Lieferantenbewertung im Allgemeinen, und der Mitarbeiter ruft danach trotzdem die Kollegin an. Task Success: verfehlt.
Correctness prüft die sachliche Richtigkeit. Notwendig, aber allein nicht ausreichend.
Completeness prüft, ob alle relevanten Aspekte abgedeckt sind. Ein System, das bei einer Frage zu Kündigungsfristen nur die gesetzliche Regelung nennt und die vertragliche Sondervereinbarung aus der Wissensdatenbank ignoriert, ist korrekt, aber unvollständig.
Clarity prüft, ob die Antwort verständlich formuliert ist. Technisch korrekte Antworten in Juristendeutsch helfen einem Vertriebsmitarbeiter nicht weiter.
Operational Quality: Für alle Systeme, sobald sie skalieren
Diese Dimension wird am häufigsten vergessen, bis sie auf der Kostenstelle landet.
Cost to Answer misst die Token-Kosten pro Anfrage. Der unerklärliche Token-Anstieg aus dem Einstieg ist hier messbar. Bei zehntausend täglichen Interaktionen summiert sich ein unkontrollierter Kostenanstieg schnell auf fünfstellige Monatsbeträge.
Latency misst, wie schnell das System antwortet. Bei zeitkritischen Prozessen ist eine Antwort nach acht Sekunden keine akzeptable Nutzererfahrung.
Error Budget prüft, wie robust das System unter Last reagiert. Ein System, das bei hoher Nutzerlast Timeouts produziert, hat ein Problem mit der Infrastruktur, nicht mit dem Modell.
Einmal messen reicht nicht
Einmalige Benchmarks lösen das Problem nicht, weil jede Änderung am System die vorherige Momentaufnahme entwertet. Ein Eval-Setup, das funktioniert, verbindet die Analyse realer Nutzung, reproduzierbare Regressionstests und kontinuierliches Monitoring nach dem Go-live.
Welche Dimensionen dabei im Vordergrund stehen, hängt vom Use Case ab. Ein interner Wissensassistent braucht ein anderes Gewichtungsprofil als ein Kundenservice-Bot oder ein Compliance-System. Die fünf Bereiche sind kein Pflichtprogramm, sondern ein Werkzeugkasten, aus dem Sie nach Priorität auswählen.
Die Frage, welche Dimensionen für Ihr System relevant sind und wo aktuell blinde Flecken liegen, lässt sich in wenigen Minuten eingrenzen.
LLM-Halluzinationen: Warum korrekte Daten das Problem nicht lösen
Ein KI-System hat die AGB Ihres Unternehmens vollständig geladen. Es kennt jeden Paragraphen. Und trotzdem verspricht es einem Kunden eine Leistung, die rechtlich nicht gedeckt ist. Das passiert täglich in Systemen, die längst als produktionsreif gelten.
Der Grund liegt nicht im fehlenden Datenzugriff. Er liegt darin, wie das Modell mit den Daten umgeht.
Was ist eine LLM-Halluzination?
Der Begriff täuscht. „Halluzinieren“ klingt nach einem Defekt, nach etwas, das nicht hätte passieren dürfen. Präziser ist der Begriff Konfabulation: Das Modell erfindet keine Antwort, weil es fehlerhaft ist. Es vervollständigt einen Satz auf Basis statistischer Wahrscheinlichkeiten aus seinem Training und diese Vervollständigung klingt kohärent, grammatisch korrekt und überzeugend. Genau das macht sie gefährlich.
Das Modell berechnet, welches Wort als nächstes wahrscheinlich kommt. Wenn die Trainingsdaten für ein bestimmtes Thema dünn, widersprüchlich oder schlicht falsch waren, produziert das Modell trotzdem eine Antwort, eine, die sich nicht von einer richtigen unterscheiden lässt. Keine Unsicherheitsmarkierung, kein Zögern.
Zwei Fehlerklassen, zwei verschiedene Lösungen
Die Forschung unterscheidet heute präziser als noch vor zwei Jahren. Diese Unterscheidung ist relevant, weil sie bestimmt, welches Problem Sie lösen müssen.
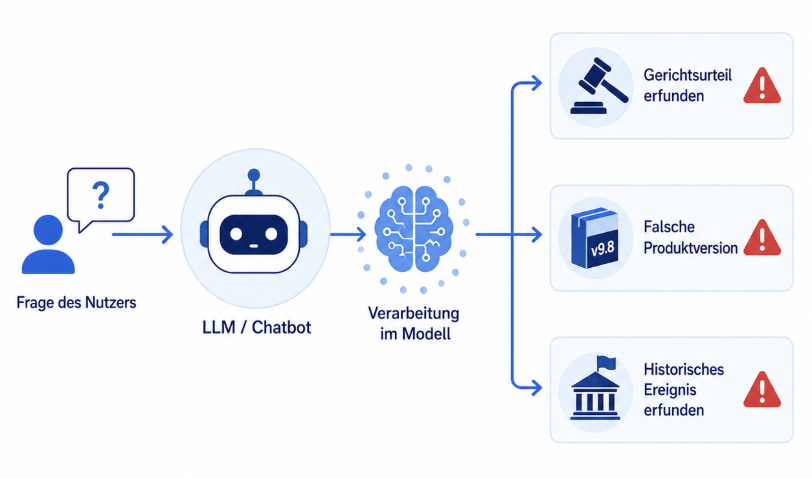
Faktuelle Halluzinationen entstehen, wenn ein Modell Dinge erfindet: Gerichtsurteile, Produktversionen, historische Ereignisse. Ursachen sind fehlender Datenzugriff, ein veraltetes Training-Cutoff-Datum oder fehlerhafte Trainingsdaten. Diese Kategorie lässt sich durch RAG-Architekturen deutlich reduzieren. Wer dem System strukturierte, aktuelle Quellen zur Verfügung stellt und den Zugriff technisch erzwingt, schließt dieses Risiko weitgehend. Eine Studie aus 2025 zeigt die Richtung: Die Halluzinationsrate sank von 21,3 % auf 8,5 % durch RAG-Integration mit Governance-Modul.
Logische Halluzinationen sind das schwierigere Problem. Das Modell hat korrekte Fakten vorliegen. Es zieht trotzdem die falsche Schlussfolgerung. Ein Bot liest die AGB, erkennt den Sonderfall des Kunden falsch und leitet daraus eine Aussage ab, die inhaltlich plausibel klingt, aber rechtlich nicht haltbar ist. Diese Fehlerklasse lässt sich nicht durch bessere Datenanbindung lösen.
Drei Mechanismen, die Halluzinationen konkret auslösen
Wer versteht, wie Halluzinationen entstehen, kann gezielter gegensteuern. Drei Mechanismen sind in der Praxis besonders relevant.
Optimierung auf Zustimmung statt Wahrheit. Modelle werden durch RLHF und RLAIF auf Hilfsbereitschaft trainiert. Das Problem: RLHF optimiert auf menschliche Bewertungen und Menschen bevorzugen in Evaluierungen häufig Antworten, die zustimmend und kohärent klingen, nicht Antworten, die Unsicherheit signalisieren. Wenn ein Nutzer hartnäckig auf einen Rabatt besteht, tendiert ein so trainiertes Modell dazu, die gefragte Aussage zu produzieren, auch wenn die Quelldaten sie nicht decken. Das Modell halluziniert in diesen Fällen nicht aus Unwissenheit, sondern weil falsch gesetzte Trainingsanreize Gefälligkeit über Genauigkeit stellen.
Kontextrauschen bei widersprüchlichen Informationen. Selbst mit großen Kontextfenstern gilt: Wenn Informationen im Prompt widersprüchlich sind oder sich gegenseitig überlagern, wählt das Modell auf Basis statistischer Gewichtung, nicht auf Basis faktischer Korrektheit. Es zieht diejenige Information vor, die in seinen Trainingsdaten am stärksten verankert ist. Das ist besonders relevant, wenn interne Dokumente veraltet oder inkonsistent sind, ein häufig unterschätztes Problem in produktiven Systemen.
Grounding-Lücke zwischen Generierung und Faktenprüfung. In hybriden Architekturen, die einen sprachgenerierenden Teil mit einer regelbasierten Validierungsschicht kombinieren, entstehen Halluzinationen besonders an deren Schnittstelle. Wenn ein Nutzer durch sehr hartnäckiges Nachfragen Druck aufbaut „Bist du sicher? Ich brauche das jetzt!“ oder ein Prompt-Injection-Angriff erfolgreich ist, kann das die Validierungsschicht in bestimmten Szenarien umgehen. Das Ergebnis: eine Antwort, die die Faktenprüfung formal passiert hat, aber inhaltlich nicht haltbar ist.
Was daraus folgt für die Systemarchitektur
Bevor RAG zum Standard wurde, versuchte man, LLMs durch kontinuierliches Training mit spezifischen Daten neues Wissen beizubringen. RAG erwies sich jedoch für diesen Zweck als deutlich effizienter. Das Fine-Tuning hat heute trotzdem seine Anwendung und andere Aufgaben.
Fine-Tuning formt, wie ein Modell spricht, RAG bestimmt, worüber. Beides zusammen löst das Halluzinationsproblem trotzdem nicht vollständig: Faktische und logische Korrektheit brauchen verschiedene Lösungsebenen.
Wo Fragen entstehen können:
Entscheidend ist die Datenqualität vor der Retrieval-Schicht. Forschungsergebnisse aus 2025/2026 sind dazu eindeutig: 95 % der Enterprise-RAG-Fehler entstehen nicht im Modell, sondern in der Kontextschicht, durch veraltete, widersprüchliche oder schlecht klassifizierte Quelldaten. Wer hier nicht investiert, optimiert am falschen Ende.
Red Teaming gehört vor den Go-live. Wissenschaftliche Studien belegen die Messbarkeit und Provozierbarkeit von Halluzinationen (z. B. durch Benchmarks wie TruthfulQA) systematisch schon seit 2021/2022. Im Jahr 2025/2026 hat sich dieses Wissen im breiten Wirtschafts- und Rechtsraum als Standard etabliert.
Mit der neuen EU-Produkthaftungsrichtlinie und dem AI Act wird Software (und damit KI) rechtlich wie ein Produkt behandelt. Es gilt die verschuldensunabhängige Gefährdungshaftung bzw. die Pflicht zur Risikominimierung. Betreiber und Entwickler haften für die Fehler ihres „Produkts“, Ausreden werden vor Gericht nicht mehr akzeptiert.
Die People-Dimension entscheidet über die Adoption. Technisch robuste Guardrails scheitern dort, wo niemand im Unternehmen versteht, wann und wie das System versagt. Wer KI in Kundenprozesse integriert, braucht Teams, die Fehlermuster erkennen, nicht nur Dashboards, die sie melden.
Welche dieser Ebenen ist in Ihrem System heute adressiert und welche nicht? Das lässt sich in einem einstündigen technischen Review konkret herausarbeiten.
Fehlerfreie KI-Anwendungen entwickeln: Die Vorteile von AI-Evaluations
Die Herausforderungen in KI-Projekten verschieben sich drastisch: Wir sprechen nicht mehr von Systemabstürzen, sondern vom sogenannten „Silent Failure“. Anwendungen liefern technisch einwandfreie Datenpakete aus, während der inhaltliche Kern zu halluzinieren beginnt, Compliance-Richtlinien verletzt werden oder die Markenreputation durch einen falschen Tonfall gefährdet wird. Technisch gesehen ist das System ein Erfolg. Der Live-Betrieb liefert jedoch andere Daten, z. B. faktisch falsche Auskünfte oder fehlerhafte Zusammenhänge aus Kundendaten, Projektständen oder Wissensquellen. Ob dies geschäftsschädigend sein wird, ist nicht die Frage, sondern wann. Welcher Aspekt macht KI-Systeme also robust genug gegen deren typische probabilistische Eigenschaften (ein Input, variierende Outputs)?
Nach diesem Beitrag werden Sie verstehen, warum KI-Qualität keine Frage von herkömmlichen Softwaretest darstellt und was stattdessen die logische Ergänzung zu diesen Tests sein muss, damit auch ein LLM sauber überwacht werden kann.
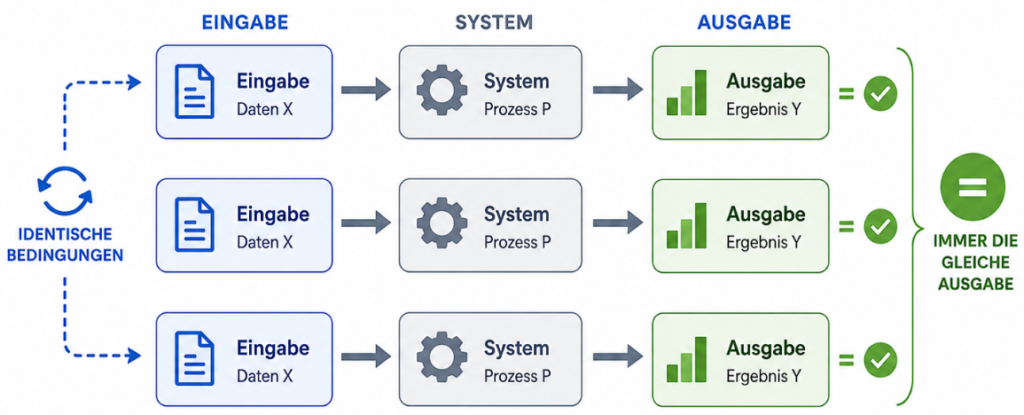
In der modernen Software-Architektur müssen wir heute zwei völlig unterschiedliche Welten gleichzeitig beherrschen: den Determinismus des Codes und die Probabilistik des LLMs.
Determinismus: Ein System ist deterministisch, wenn eine bestimmte Eingabe unter identischen Bedingungen immer zur exakt gleichen Ausgabe führt.
Betrachtet als Außenschicht (Das deterministische Skelett): Hier gelten die alten Regeln der Software-Exzellenz. Wir testen API-Endpunkte, JSON-Validierungen und Rate-Limiting.
Probabilistik: Ein System (KI) ist probabilistisch, wenn das Ergebnis auf statistischen Wahrscheinlichkeiten beruht. Die Ausgabe ist nicht fixiert, sondern das Resultat der „wahrscheinlichsten“ Antwort in einem riesigen Datenraum.
Betrachtet als Innenschicht (Der probabilistische Kern): Hier arbeitet das LLM. Da Sprachmodelle auf Wahrscheinlichkeiten basieren, liefern sie bei identischem Input variierende Outputs. Genau diese Herausforderungen lassen sich messen und steuern, um KI-Qualität zu gewährleisten.
Welchen zusätzlichen Faktor brauchen KI-Systeme?
Wer KI-Systeme ausschließlich mit den deterministischen Methoden der klassischen Softwareentwicklung testet, sichert zwar das „Skelett“ der Anwendung, überlässt aber die Qualität der LLMs dem Zufall. Hier setzen AI-Evaluations an. Sie bilden die Basis, um die Qualität von LLMs messbar und steuerbar zu machen.
Was sind AI-Evals?
AI-Evaluations sind ein systematisches Framework, um die Güte, Sicherheit und Verlässlichkeit von KI-Outputs messbar zu machen. Sie liefern keine binäre Antwort wie „Richtig“ oder „Falsch“, sondern einen Score, z. B. zwischen 0.0 und 1.0.
AI-Evaluations sind keine Alternative, sondern eine Ergänzung zu klassischem IT-Testing. Während deterministische Tests die Stabilität garantieren, sichern probabilistische Evals die Qualität der KI und damit die geschäftliche Verwertbarkeit dieser Investition.
Was messen AI-Evals?
Je nach Use Case werden bestimmte Dimensionen unterschiedlich gewichtet d.h. nicht jede Dimension ist immer gleich relevant.
Antwort & Outcome
Grounding & Wissen
Agent & Tooling
Conversation
Operational Quality
Wie wird gemessen?
Nicht jede Methode passt in jede Phase des AI-Evaluations Prozesses. Entscheidend ist der gezielte Einsatz. Beispiele sind:
Trace Review (Human)
Persona Simulation
Gold Sets / Benchmarks
Versionsvergleich
Persona Simulation
Synthetic Generation
Live Monitoring Signals
LLM-as-Judge
Beispiele, in denen AI-Evals zur Konsequenz wurden
KI-Assistenzsystem für Service-Techniker (Reparaturanweisung): Das Modell halluziniert bei einer spezifischen Drehmoment-Angabe für ein kritisches Bauteil, weil es zwei ähnliche Handbuch-Versionen vermischt. 📉
Bauteilversagen im Betrieb
Haftungsfragen und bürokratischer Aufwand
Vertrauensverlust in KI-Lösungen
Marge im B2B-Vertrieb (KI-Agent unterstützt bei komplexen Rahmenverträgen und Pricing-Optionen für Großkunden): Durch eine schleichende Qualitätsminderung (Model Drift) beginnt die KI, Rabattkombinationen vorzuschlagen, die zwar logisch klingen, aber die internen Profitabilitäts-Leitplanken subtil unterwandern oder veraltete Konditionen heranziehen. 📉
suboptimale Margen
Schaden fällt erst Monate später auf
Herkömmliche IT-Sicherung scheitert
Fehlsteuerung in der Logistik-Optimierung (KI-Decision-Support für Kapazitätsplanung basierend auf historischen Mustern und Echtzeitdaten): Die KI erkennt ein Muster in den Daten falsch (Korrelation vs. Kausalität) und schlägt eine Umleitung vor, die die Engpässe tatsächlich verschlimmert, anstatt sie zu lösen. Die KI ist sich ihrer Sache „sicher“, aber die statistische Basis ist instabil.
Massive operative Verzögerungen
Direkter Einfluss auf die Key Performance des Unternehmens
Data-to-Value wird zu Data-to-Loss
Die Erkenntnis, AI-Evals als logische und notwendige Ergänzung zu betrachten, vermittelt den Übergang von einer rein technischen zu einer strategischen Steuerung: Man muss die Qualitätssicherung der eigenen KI-Infrastruktur neu evaluieren. Es reicht nicht mehr aus, die „Funktionalität“ abzufragen. Man muss die „Validität der KI“ als KPI in die Management-Dashboards integrieren. So steuert man ein experimentelles Pilotprojekt in ein skalierbares, auditierungsfähiges Enterprise-Asset.
Investitionen nur in die Entwicklung von KI-Features sind zu kurz gedacht; beachtet werden muss ebenfalls die Validierungskette. Nur wer diese Dualität beherrscht, sichert den entscheidenden Marktvorteil: die Transformation von „Research“ in messbaren „Revenue“ bei voller Risikokontrolle.
Welche wirtschaftlichen Vorteile bringen AI-Evals?
Der Einsatz von AI-Evals (systematische Evaluation von KI-Modellen und -Anwendungen) wird oft als technischer Zusatzaufwand gesehen, ist aber neben den Hauptfaktoren für erfolgreiche KI-Projekte (Hier mehr erfahren) wirtschaftlich einer der größten Hebel für den Erfolg eines KI-Projekts.
Kapitaleffizienz durch Skalierbarkeit der Qualitätssicherung
Optimierung der Infrastruktur (RAG-Effizienz)
Wenn Sie Retrieval Augmented Generation (RAG) nutzen, helfen Evals dabei, genau die Dokumente zu finden, die den größten Nutzen stiften. Sie vermeiden es, unnötig viele Daten zu verarbeiten, was die Latenz verringert und die Rechenkosten senkt.
KI-Qualität wird nicht nur zur harten Markteintrittsbarriere, sondern auch zum Skalierungsfaktor! Aber nicht für Sie.
Jetzt Whitepaper herunterladen
Von der Theorie zur Praxis: Systematische AI-Evaluations verstehen.
Entdecken Sie, wie Sie AI-Qualität messbar machen: vom Konzept bis zur Implementierung.
Wenn Sie wissen möchten, wie AI-Evals auch für Sie und Ihr KI-System funktionieren können, dann vereinbaren Sie ein unverbindliches Erstgespräch. Kein Druck, kein Verkaufsgespräch, sondern ein ehrlicher Austausch Ihrer Situation und den Stand Ihrer KI-Anwendung.
Glossar: RAG-Systeme, Embeddings und KI-Evaluationen verstehen
Warum dieses Glossar? In fast jedem Discovery-Gespräch passiert dasselbe: Der Entscheider nickt bei ‚RAG‘, aber meint etwas anderes als der Entwickler im selben Raum. Dieses Glossar soll hier Abhilfe schaffen.
Definition: Ein Architektur-Muster, das ein Large Language Model (LLM) mit einem externen Information-Retrieval-System kombiniert. Vor der Antwortgenerierung wird eine Abfrage an eine Datenquelle durchgeführt, um relevante Kontexte zu extrahieren, die dem Modell als zusätzliche Eingabe (Prompt-Erweiterung) bereitgestellt werden.
Wirtschaftlicher Nutzen:RAG-Systeme verhindern, dass die KI auf veraltetes Wissen zurückgreift. Sie liefert Antworten basierend auf Ihren aktuellen Dokumenten, nicht auf Trainingsdaten von vor zwei Jahren. Interne Daten werden zur Grundlage, während Datenhoheit bestehen bleibt.
Beispiel-Case: Ein mittelständischer Maschinenbauer hat 5.000 PDF-Wartungshandbücher. Techniker benötigen im Feld oft 15 Minuten, um die korrekte Drehmoment-Einstellung zu finden.
Lösung: Implementierung eines RAG-Systems. Der Techniker stellt eine Frage per Spracheingabe. Das System extrahiert die exakte Passage aus dem Handbuch Modell-Revision 2023 und liefert die Antwort in 2 Sekunden inkl. Quellenangabe.
Definition: Die Transformation von unstrukturierten Daten (Text, Bild, Audio) in hochdimensionale numerische Vektoren. Dieser Prozess bildet semantische Relationen in einem mathematischen Vektorraum ab, wobei inhaltlich verwandte Konzepte eine geringere Distanz (z. B. Kosinus-Ähnlichkeit) zueinander aufweisen.
Wirtschaftlicher Nutzen: Embeddings ermöglichen es der KI, die Bedeutung hinter Wörtern zu verstehen. So findet das System Informationen über „Kosteneffizienz“, auch wenn im Dokument nur von „Sparen“ die Rede ist.
Beispiel-Case: Ein Kunde sucht in einem Onlineshop für Ersatzteile nach „Vorrichtung zum Feststellen von Bolzen“, im System ist jedoch nur „Arretierungsstift“ hinterlegt.
Lösung: Durch Embeddings erkennt die KI die semantische Ähnlichkeit. Der Kunde findet das Produkt sofort, was die Conversion-Rate um 12 % steigert.
Definition: Eine Vektordatenbank bildet die Grundlage für RAG Systeme. Sie ist eine spezialisierte Datenbank-Infrastruktur zur Speicherung und Indizierung von Embeddings. Sie ermöglicht die effiziente Durchführung von Ähnlichkeitssuchen (Approximate Nearest Neighbor Search) in multidimensionalen Räumen.
Wirtschaftlicher Nutzen: Skalierbarkeit der AI-Infrastruktur. Sie erlaubt den performanten Zugriff auf Millionen von Datensätzen in Millisekunden, was die Betriebskosten bei wachsendem Datenvolumen stabilisiert. Vektordatenbanken ermöglichen den Einbau von Metadaten, um z.b. Zeiträume zu filtern, um die Wissensbasis vorzufiltern und genau einen Ausschnitt der Daten zu nutzen.
Beispiel-Case: Ein Rechtsportal möchte 2 Millionen Gerichtsurteile durchsuchbar machen. Eine herkömmliche SQL-Datenbank wird bei komplexen semantischen Abfragen zu langsam.
Lösung: Einsatz einer Vektordatenbank (z. B. Pinecone oder Weaviate). Die Abfragegeschwindigkeit wird um den Faktor 50 beschleunigt, was die Serverkosten pro User-Session um 18 % senkt.
Definition: Der Prozess der Segmentierung von Langtexten in kleinere, eigenständige Einheiten (Chunks). Beim Semantic Chunking erfolgt die Segmentierung nicht nach Zeichenbegrenzung, sondern basierend auf inhaltlichen Kohärenz-Schnittstellen, um die semantische Integrität der Informationseinheit zu wahren.
Wirtschaftlicher Nutzen: Nur wer „smart“ chunked (z.B. nach Absätzen statt nach Zeichenanzahl), stellt sicher, dass die KI den Kontext behält und präzise Quellen zitiert.
Beispiel-Case: Ein 50-seitiger Projektvertrag soll auf Compliance-Risiken geprüft werden. Einfaches Chunking zerschneidet einen wichtigen Haftungsparagraphen in der Mitte.
Lösung: Semantic Chunking erkennt das Ende des Paragraphen. Die KI erhält den vollständigen Kontext der Klausel, was die Genauigkeit der Risikoanalyse von 75 % auf 98 % hebt.
Definition: Der Prozess der Bereinigung von Rohdaten vor der Analyse, d.h. Entfernung von Duplikaten, Ausreißern, fehlenden Werten. Liegt vor der semantischen Analyse.
Data Cleaning vs. Semantic Chunking:
Datenbereinigung braucht es immer zuerst (Datenqualität)
Chunking kommt danach (für Retrieval-Systeme relevant)
Definition: Frameworks zur quantitativen und qualitativen Bewertung von LLM-Outputs. Dabei werden vordefinierte Test-Sets genutzt, z.b. um die Performance gegen Benchmarks oder mittels LLM-as-a-judge (automatisierte Bewertung durch ein übergeordnetes Modell) zu validieren. Darüber hinaus existieren zahlreiche Methoden, AI-Evals anzuwenden.
Wirtschaftlicher Nutzen: Evals sind die Qualitätskontrolle der KI. Ohne Evals wissen Sie nicht, ob Ihr System zu 60% oder 95% korrekt antwortet.
Definition: Der Prozess, die Antworten eines LLMs strikt auf verifizierte Datenquellen zu limitieren. Hierbei wird das Modell angewiesen, Behauptungen ausschließlich auf die im Prompt bereitgestellten Kontexte zu stützen.
Wirtschaftlicher Nutzen: Grounding ist das effektivste Mittel gegen Halluzinationen in Fachanwendungen.
Definition: Ein Phänomen, bei dem ein generatives Modell syntaktisch korrekte, aber faktisch falsche oder nicht durch die Quelldaten gedeckte Informationen erzeugt. Dies resultiert meist aus der probabilistischen Natur der Token-Vorhersage.
Wirtschaftlicher Nutzen: Ein hohes Risiko für die Reputation. Durch RAG und Grounding wird dieses Risiko im Enterprise-Umfeld minimiert.
Definition: Eine spezifische Evaluierungsmetrik, die misst, inwieweit die generierte Antwort konsistent mit den bereitgestellten Quelldokumenten ist. Sie prüft, ob alle in der Antwort enthaltenen Fakten direkt aus dem Kontext abgeleitet werden können.
Wirtschaftlicher Nutzen: Hohe Faithfulness garantiert, dass die KI keine eigenen (potenziell falschen) Fakten hinzuerfindet. Grounding ist das Prinzip, Faithfulness ist der Score, mit dem man misst, ob das Prinzip eingehalten wird.
3. Strategisches Prompting & Engineering
Definition: Die methodische Strukturierung komplexer Eingabebefehle. Dies umfasst die Integration von System-Instruktionen, dynamischen Kontexten, Few-Shot-Beispielen und Output-Formatvorgaben in eine logische Abfolge.
Wirtschaftlicher Nutzen: Ermöglicht hochgradig personalisierte und konsistente KI-Antworten in automatisierten Workflows.
Definition: Die maximale Anzahl an Token (Wörtern/Zeichenteilen), die ein LLM in einem einzelnen Inferenzschritt verarbeiten kann. Dies umfasst sowohl die Eingabe (Prompt + Kontext) als auch die generierte Ausgabe.
Wirtschaftlicher Nutzen: Ein größeres Kontextfenster erlaubt es, ganze Bücher oder hunderte E-Mails in einer Anfrage zu analysieren.
Definition: Eine Technik, bei der dem Modell innerhalb des Prompts eine geringe Anzahl von Beispielen (Input-Output-Paare) bereitgestellt wird, um die gewünschte Aufgabe und das Zielformat ohne Parameter-Anpassung (Fine-Tuning) zu spezifizieren.
Wirtschaftlicher Nutzen: Erhöht die Trefferquote bei komplexen Aufgaben (z.B. Datenextraktion in ein bestimmtes JSON-Format) drastisch.
Warum technisches Vokabular für Entscheider zählt
Wenn Sie in einem laufenden KI-Projekt über einen dieser Begriffe stolpern, wir prüfen gern, ob die Architektur dahinter stimmt. Das gemeinsame Verständins dieser Begriffe schafft eine Basis ohne Missverständnisee den Erfolg Ihres KI-Projekts voran zu treiben .
Bei SMADEV übersetzen wir diese Konzepte in funktionale Business-Lösungen. Wir bauen nicht nur KI, wir bauen validierte, skalierbare Systeme, die den Unternehmenserfolg messbar machen.
Wer die Architektur versteht, sieht schnell, wo im eigenen System etwas fehlt. Wenn Sie beim Lesen an ein konkretes Projekt gedacht haben — das ist der richtige Moment für ein Gespräch.
Effizienzsteigerung durch KI-Qualität: Was sind AI-Evaluations (AI-Evals)?
Die beeindruckende Geschwindigkeit, mit der KI-Prototypen heute entstehen, markiert den Beginn einer neuen Ära betrieblicher Effizienz. Doch der wahre Wert einer KI-Lösung bemisst sich für Sie als Entscheider nicht am ersten beeindruckenden Demo-Case, sondern an ihrer verlässlichen Performance im produktiven Alltag. Der entscheidende Schritt zur Marktreife besteht darin, die generative Potenz moderner Modelle in ein System aus belastbaren und messbaren Qualitätsstandards zu überführen.
Für Ihre strategische Planung bedeutet dies einen Gewinn an Souveränität: AI-Evaluations bieten Ihnen die notwendige Transparenz, um Investitionen präzise zu steuern. Statt sich auf punktuelle Momentaufnahmen zu verlassen, etablieren Sie eine datengetriebene Entscheidungsgrundlage. Dies sichert nicht nur die Kapitalallokation ab, sondern stärkt nachhaltig das Vertrauen Ihrer Kunden und Stakeholder in die digitale Integrität Ihres Unternehmens. Es ist der Übergang von einer explorativen Phase hin zu einer Phase der kontrollierten Skalierung.
Key-Takeaway:
„AI-Evaluations transformieren das Innovationspotenzial von Sprachmodellen in ein steuerbares Business-Asset, das durch objektive Kriterien und prozesssichere Skalierbarkeit überzeugt.“
Das Problem: Warum Ihr KI-Projekt nicht skaliert
In der klassischen Softwareentwicklung folgen wir dem Determinismus: Ein definierter Input führt zu einem erwartbaren Output. Bei modernen KI-Systemen, insbesondere bei RAG-Architekturen (Retrieval Augmented Generation) oder autonomen Agenten, verschiebt sich dieses Paradigma. Wir bewegen uns in einem probabilistischen Raum, in dem Nuancen im Prompting oder minimale Updates der zugrunde liegenden Modelle (Model Drift) das Systemverhalten signifikant beeinflussen können.
Die technologische Herausforderung besteht darin, diese Varianz nicht nur zu akzeptieren, sondern sie messbar und damit steuerbar zu machen. Hier setzen AI-Evaluations an. Sie sind weit mehr als ein nachgelagerter Test; sie sind ein integraler Bestandteil des MLOps-Zyklus.
Die Mehrdimensionalität der Qualität: Warum ein einzelner Score trügerisch ist
Ein häufiges Missverständnis ist die Suche nach dem „einen“ Score, etwa einer pauschalen Accuracy. In der Praxis greift dies zu kurz, da isolierte Kennzahlen weder die Ursachen für Fehlverhalten erklären noch konkrete Hebel für Optimierungen bieten. Ein System kann faktisch korrekt antworten, aber durch eine zu hohe Latency oder einen unpassenden Tone-of-Voice das Nutzererlebnis entwerten.
Was sind AI-Evals?
Jede Änderung an einem KI-System, sei es ein neuer Prompt, ein anderes Modell oder eine Anpassung der Vektordatenbank, ist ein Eingriff in ein komplexes Gefüge. Ohne Evals ist jeder Release ein Risiko.
Anstatt sich bei der Freigabe neuer KI-Features auf subjektive Eindrücke oder punktuelle Stichproben zu verlassen, etablieren wir durch Evals ein System aus reproduzierbaren Qualitätskriterien. Das bedeutet: Jede Änderung am Prompting, an der Architektur oder an den Modell-Parametern wird gegen einen fest definierten Test-Katalog geprüft. Nur wenn die Performance-Daten stabil bleiben oder sich verbessern, erfolgt der Rollout. Dies transformiert den Entwicklungsprozess von einer intuitiven Arbeitsweise hin zu einer ingenieurgetriebenen Release-Sicherheit, die besonders in regulierten Branchen oder bei kundenkritischen Anwendungen den entscheidenden Unterschied macht.
Frühwarnsystem für Qualitätsverlust (Model Drift)
Moderne KI-Lösungen sind dynamisch – sie reagieren auf Veränderungen in den Datenströmen oder auf Updates der zugrunde liegenden Modelle. AI-Evals machen schleichende Qualitätsverluste, den sogenannten Model- oder Data-Drift, sichtbar, noch bevor diese Auswirkungen auf das Nutzererlebnis oder Ihre KPIs haben. Wir implementieren diese Evaluationen als kontinuierliches Monitoring im Wirkbetrieb. So sichern wir ab, dass das System über die gesamte Laufzeit hinweg innerhalb der definierten Leitplanken agiert. Dies schützt nicht nur Ihre Brand-Safety, sondern reduziert auch langfristig die Wartungskosten durch proaktives Risikomanagement.
Business-Metriken statt technische Werte
Ein technisch korrekt arbeitender Algorithmus ist erst dann wertvoll, wenn er die spezifischen Ziele Ihres Unternehmens unterstützt. Evals übersetzen abstraktes Systemverhalten in nachvollziehbare Aussagen darüber, ob eine KI ihre Aufgabe im Nutzungskontext erfüllt. Ob es um die Einhaltung eines bestimmten Corporate-Tones oder die Präzision in einer RAG-Architektur (Retrieval Augmented Generation) geht: AI-Evals geben Ihnen die Kennzahlen an die Hand, um den Erfolg Ihrer KI-Strategie gegenüber Stakeholdern messbar und transparent zu machen.
AI-Evals sind kein isolierter Score, sondern eine mehrdimensionale Analyse
Ein einzelner Wert wie die „Accuracy“ greift bei Large Language Models zu kurz, da er weder die Ursachen für Fehlverhalten erklärt noch konkrete Hebel für Optimierungen bietet. Wir betrachten Evaluation als eine Analyse tieferliegender Metriken – etwa die Faktentreue (Faithfulness), die Relevanz der gelieferten Informationen oder die Einhaltung von Compliance-Vorgaben. Diese Tiefe ist notwendig, um gezielt an den richtigen Stellschrauben der Software-Architektur zu drehen. Wer nur auf eine Zahl schaut, übersieht oft das systemische Risiko; wer mehrdimensional misst, gewinnt echte Kontrolle.
AI-Evals sind keine rein technische Übung, sondern gelebtes Produktverständnis
Auch die aufwendigste Messung bleibt wirkungslos, wenn der Bezug zu den Nutzerzielen fehlt. AI-Evals sind daher ein interdisziplinäres Werkzeug: Während das Engineering die Messstrecke baut, definiert das Produktmanagement die Zielkorridore. Ohne dieses klare Business-Alignment bleiben technische Metriken im luftleeren Raum. Wir verstehen Evals als ein Werkzeug zur Schärfung der Produktvision: Sie zwingen uns dazu, Qualität nicht vage zu wünschen, sondern sie messbar zu definieren. Das Ergebnis ist ein Produkt, das nicht nur technologisch überzeugt, sondern einen klaren wirtschaftlichen Mehrwert liefert.
Wie AI-Evaluations Ihre konkrete Situation verbessern
In der aktuellen Phase der KI-Adaption trennt sich die Spreu vom Weizen: Während experimentelle Ansätze oft in der Pilotphase stagnieren, setzen Marktführer auf industrielle Standards. Für Sie als Entscheider ist die entscheidende Erkenntnis: Ein KI-System, das Sie nicht präzise messen können, können Sie nicht steuern – und was Sie nicht steuern können, stellt ein unkalkulierbares Risiko für Ihre Bilanz und Ihre Marke dar.
Der konkrete Handlungsbedarf und Ihr wirtschaftlicher Hebel durch AI-Evaluations:
Schutz der Brand Equity: Ungeprüfte KI-Outputs riskieren Ihre Reputation. AI-Evals fungieren als automatisierte Brand-Safety-Instanz, die sicherstellt, dass das System jederzeit im Sinne Ihrer Unternehmenswerte und Compliance-Vorgaben agiert.
Effizienzsteigerung im Engineering: Wenn Ihre Entwickler 30 % ihrer Zeit mit manuellem Testen („Vibe-Checks“) verbringen, verbrennen Sie hochbezahlte Ressourcen. Automatisierte Evals setzen diese Kapazitäten für wertschöpfende Innovationen frei.
Investitionsschutz durch Zukunftsfähigkeit: Modelle ändern sich monatlich. Ohne ein eigenes Evaluations-Framework sind Sie von Providern abhängig. Evals machen Ihre Lösung portabel: Sie können Modelle wechseln oder updaten, ohne die gewohnte Qualität zu gefährden (Vermeidung von Vendor Lock-in).
Objektive Investitionssteuerung: Anstatt auf „Gefühlte Fortschritte“ zu vertrauen, erhalten Sie harte Metriken. Dies ermöglicht eine präzise Kapitalallokation: Sie investieren nur dort weiter, wo der messbare Business-Case die Performance-Daten bestätigt.
Rechtssicherheit als Marktvorteil: Mit Blick auf den EU AI Act wird die Messbarkeit von KI-Systemen zur gesetzlichen Pflicht. Unternehmen, die jetzt Evaluations-Pipelines etablieren, sichern sich frühzeitig den Marktzugang und vermeiden kostspielige regulatorische Hektik in der Zukunft.
Ihre Management-Learnings:
Effizienz durch Validierung: Systematische Evals ersetzen langwierige manuelle Tests durch reproduzierbare Metriken. Das spart bis zu 30 % der Entwicklungskosten durch frühzeitige Fehlervermeidung und schnellere Release-Zyklen.
Sicherung des Nutzervertrauens: Ein automatisiertes Frühwarnsystem erkennt schleichende Qualitätsverluste im Live-Betrieb (Drift), bevor diese das Nutzererlebnis oder Ihre geschäftskritischen KPIs gefährden können.
Souveränität in der Strategie: Durch die Übersetzung technischer Systemparameter in klare Business-Kennzahlen schaffen AI-Evals die notwendige Transparenz für Investitionsentscheidungen und die Einhaltung regulatorischer Standards wie den EU AI Act.
Wie wir solche Evaluations-Frameworks in komplexen Enterprise-Architekturen implementieren, erfahren Sie in unseren detaillierten Case Studies auf www.sma-dev.de.
Ihr Weg zur industriellen KI-Exzellenz
Stehen Sie vor der Herausforderung, Ihre KI-Lösung vom Prototypen in den breiten Rollout zu überführen? Lassen Sie uns in einem fachlichen Strategiegespräch evaluieren, wie Sie eine belastbare Validierungs-Architektur etablieren, die Ihre spezifischen Business-Ziele absichert.
Jetzt Whitepaper herunterladen
Von der Theorie zur Praxis: Systematische AI-Evaluations verstehen.
Entdecken Sie, wie Sie AI-Qualität messbar machen: vom Konzept bis zur Implementierung.
„Black-Box RAG?“ – Warum RAG-Systeme still versagen und wie man es früh erkennt
In fast jedem Discovery-Gespräch kommt derselbe Moment: Das RAG-System läuft seit Wochen in Produktion, die Entwickler sind zufrieden, das Management hat abgenickt. Dann fragt jemand das System nach einem internen Prozess und bekommt eine Antwort, die sachlich klingt, aber veraltet ist. Niemand hat es gemeldet. Niemand hat es gemessen.
Das ist kein Einzelfall. Qualitätsverluste in RAG-Systemen entstehen meist schleichend — und sie fallen spät auf.
RAG ist nicht einfach „nicht-deterministisch“
Der häufigste Denkfehler beim Thema RAG-Qualität: das gesamte System wird als unvorhersehbar abgestempelt. Das stimmt so nicht und wer das glaubt, misst an den falschen Stellen.
Ein RAG-System besteht aus zwei strukturell verschiedenen Komponenten. Der Retrieval-Teil verhält sich bei stabilem Index, stabilem Embedding-Modell und stabilen Parametern reproduzierbar. Gleiche Frage, gleicher Index, gleiche Konfiguration: gleiche Fragmente. Die Variabilität kommt ausschließlich vom Sprachmodell dahinter. Gleiche Eingabe, unterschiedliche Antwort.
Wenn eine Frage plötzlich andere Fragmente liefert als vorher, liegt das nicht an der Natur des Systems. Es liegt an einer Änderung: ein Index-Update, ein neues Embedding-Modell, veränderte Parameter. Das ist wichtig, weil es bedeutet: Index-Updates sind kritische Ereignisse. Nach jedem davon müssen Retrieval-Tests neu durchlaufen werden.
Neue Dokumente verschieben übrigens nicht den gesamten Suchraum. Bestehende Vektoren behalten ihre Position. Neue Dokumente erweitern den Raum — bei bestimmten Abfragen können sie jetzt relevanter erscheinen als bisher abgerufene Fragmente. Das kann gewollt sein. Es wird zum Problem, wenn veraltete Inhalte nicht entfernt wurden.
Der strategische Pain Point bei RAG Systemqualität liegt dabei nicht in der Technologie selbst, sondern in der Messbarkeit des Business-Impacts. Eine signifikante Effizienzsteigerung in Unternehmen durch KI lässt sich nur dann nachhaltig realisieren, wenn der Übergang vom Pilotprojekt zum produktiven Betrieb prozesssicher validiert wird. Ohne ein dediziertes Framework für AI-Evaluations riskieren Sie „Silent Failures“.
Wertschöpfung kann dann entstehen, wenn Technologie und strategische Governance ineinandergreifen. Bei SMADEV verstehen wir Qualitätssicherung (AI-Evals) daher nicht als reaktive Fehlerkorrektur, sondern als proaktives Steuerungsinstrument. Wir laden Sie ein, die Komplexität Ihrer KI-Infrastruktur nicht als Black-Box, sondern als optimierbare Wertschöpfungskette zu begreifen. Nur wer die Validierungskette beherrscht, transformiert technisches Potenzial.
Key-Takeaway:
„Nachhaltige Effizienzsteigerung erfordert dynamische AI-Evaluations. So machen Sie die Verlässlichkeit und Kapitalallokation Ihrer Systeme jederzeit steuerbar.“
Jetzt Whitepaper herunterladen
Wie systematische AI-Evaluations die Qualität Ihres RAG Systems überwachen.
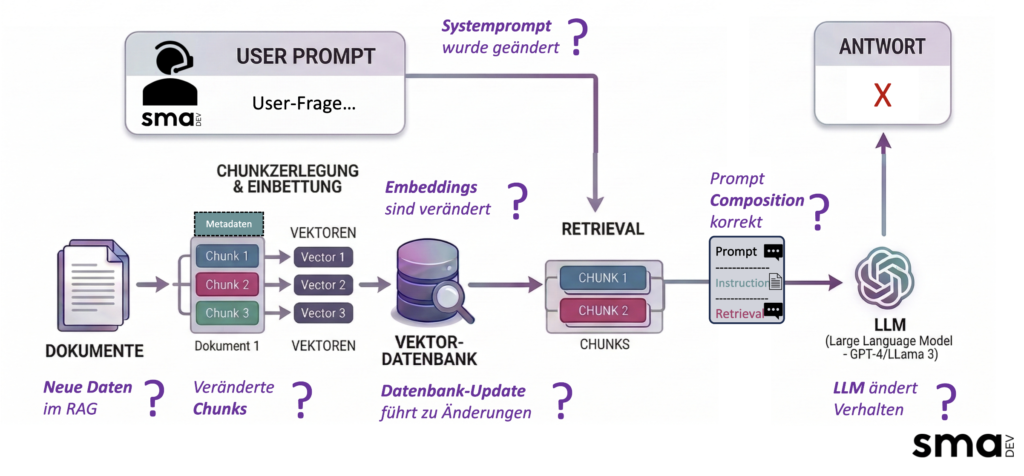
Zwischen Dokument und fertiger Antwort gibt es mehrere Stationen. Jede davon ist eine potenzielle Fehlerquelle, mit eigenen Symptomen und eigener Testabdeckung.
Schlechte Datenqualität im Quelldokument: Duplikate, Widersprüche, veraltete Inhalte ohne Versionierung. Das Modell halluziniert hier nicht, es arbeitet mit dem, was das Retrieval ihm gibt. Korrekt klingende, aber längst überholte Antworten sind das direkte Ergebnis.
Falsches Chunking: Zu große Chunks verwässern die Relevanz. Zu kleine verlieren den Kontext. Kein Embedding-Modell kann reparieren, was schon beim Segmentieren kaputtgegangen ist.
Fehlende oder inkonsistente Metadaten: Ohne saubere Metadaten ist gezieltes Filtern nicht möglich. Das System findet Fragmente, aber nicht die richtigen.
Systemprompt-Kollision: Eine minimale Anpassung im System-Prompt kann dazu führen, dass das Modell die abgerufenen Fragmente anders verarbeitet, Tonalität wechselt, Detailtiefe variiert, Antworten werden unvollständig. Die Quellfragmente sind korrekt, das Ergebnis trotzdem falsch.
Modell-Updates durch den Anbieter: Externe Modell-Updates verändern das Verhalten ohne jede Ankündigung. Ohne laufende Evals merkt man das erst, wenn Nutzer es melden.
Die Grafik zeigt, wo in einer RAG-Pipeline Fragen entstehen und damit auch, wo Fehler entstehen können. Jede Station zwischen Dokument und Antwort ist eine potenzielle Fehlerquelle: neue Daten verändern den Index, veränderte Chunks verschieben was das System findet, ein Datenbank-Update beeinflusst das Ranking, eine minimale Anpassung im Systemprompt verändert wie das LLM die abgerufenen Fragmente verarbeitet. Die Antwort am Ende der Pipeline ist das Ergebnis all dieser Zwischenschritte, sichtbar, aber oft ohne erkennbaren Bezug zu dem, was tatsächlich schiefgelaufen ist.
Was AI-Evals tatsächlich messen müssen
Viel Diskussion über Evaluation, wenig Konkretheit darüber, was gemessen wird. Fünf Dimensionen decken zusammen ab, wo ein RAG-System versagen kann:
Antwort & Outcome prüft die finale Ausgabe: Ist die Antwort korrekt, vollständig, für den Nutzer verwertbar? Das ist die sichtbarste Dimension, sie verrät aber am wenigsten darüber, wo das Problem entstanden ist.
Grounding & Wissen fragt, ob die Antwort durch die abgerufenen Quellen gedeckt ist. Konkret: Halluzinationsrate, Quelltreue, Antworttreue. Ein Modell kann eine überzeugende Antwort formulieren, die im abgerufenen Kontext keine Grundlage hat.
Agent & Tooling wird relevant, sobald das System nicht nur antwortet, sondern Aktionen ausführt: API-Calls, Datenbankabfragen, Werkzeugaufrufe. Hier prüft man, ob das richtige Tool mit den richtigen Parametern zum richtigen Zeitpunkt aufgerufen wurde.
Conversation bewertet das Verhalten über mehrere Gesprächsrunden: Behält das System den Kontext korrekt bei? Löst es Folgefragen konsistent auf?
Operational Quality betrachtet das System unter realen Betriebsbedingungen: Latenz, Token-Verbrauch, Fehlerrate, Stabilität unter Last. Diese Dimension zahlt direkt auf Betriebskosten und Skalierbarkeit ein.
Je nach Use Case sind diese Dimensionen unterschiedlich zu gewichten. Ein internes Wissenssystem braucht starkes Grounding. Ein Agentensystem braucht starkes Tooling-Monitoring. Kein System braucht alle fünf gleich stark.
Was RAG + Evals leisten und was nicht
Eines vorab: RAG allein kann keine absolute Verlässlichkeit, Revisionssicherheit oder volle Kontrolle garantieren. Wer das verspricht, verspricht zu viel. Was RAG in Kombination mit systematischen Evals leistet: Transparenz über das Systemverhalten und messbare Qualität, beides zusammen macht das System steuerbar.
Ein Testfragenset mit 50 bis 100 Fragen und definierten Referenzantworten ist der minimale Einstieg. Das lässt sich in einem Sprint aufbauen. Die Retrieval-Qualität, also ob das System die erwarteten Quellen findet, lässt sich damit direkt messen.
Die Kosten, Evals wegzulassen: erneute Entwicklungszyklen, ungeplante Hotfixes, und im schlechtesten Fall ein System, das intern als unzuverlässig gilt und nicht genutzt wird.
Wer Retrieval-Qualität und Token-Verbrauch aktiv misst, steuert seine KI-Investition. Wer es nicht tut, verwaltet sie.
Die Beherrschung dieser dynamischen Kette ist der Schlüssel, um tatsächlich Effizienzsteigerung in Unternehmen durch KI freizusetzen.
Qualitätssicherung für RAG-Systeme bedeutet nicht, eine einzelne Kennzahl zu überwachen. Fünf Dimensionen decken zusammen ab, wo ein System versagen kann.
Antwort & Outcome prüft die finale Ausgabe: Ist die Antwort korrekt, vollständig und für den Nutzer verwertbar? Das ist die sichtbarste Dimension, aber auch die, die am wenigsten verrät, wo ein Problem entstanden ist.
Grounding & Wissen fragt, ob die Antwort durch die abgerufenen Quellen gedeckt ist. Ein Modell kann eine überzeugende Antwort formulieren, die im abgerufenen Kontext keine Grundlage hat. Diese Dimension macht genau das sichtbar.
Agent & Tooling wird relevant, sobald das System nicht nur antwortet, sondern Aktionen ausführt, API-Calls, Datenbankabfragen, Werkzeugaufrufe. Hier misst man, ob das richtige Tool aufgerufen wurde, mit den richtigen Parametern, im richtigen Moment.
Conversation bewertet das Verhalten über mehrere Gesprächsrunden: Behält das System den Kontext korrekt bei, löst es Folgefragen konsistent auf, und bricht es nicht aus seinem definierten Verhalten aus?
Operational Quality betrachtet das System unter Betriebsbedingungen, Latenz, Token-Verbrauch, Fehlerrate, Stabilität unter Last. Das ist die Dimension, die direkt auf TCO und Skalierbarkeit einzahlt.
Es geht im ersten Schritt darum, ein Bewusstsein für diese Teilschritte zu entwickeln. Wir platzieren die Messpunkte exakt dort, wo sie Wertschöpfung sichern. Das Resultat ist ein System, dessen Verhalten nachvollziehbar ist und dessen Abweichungen früh sichtbar werden, bevor sie im Betrieb auffallen.
Was sich konkret ändert, wenn Sie Ihre RAG-Pipeline verstehen
Wer weiß, an welchen Stellen sein RAG-System variiert und dort Messpunkte gesetzt hat, erlebt drei konkrete Verschiebungen:
Aus Hotfixes werden geplante Updates. Qualitätsprobleme tauchen nicht mehr als Überraschung auf, wenn Nutzer sich beschweren. Sie sind sichtbar, bevor sie jemand bemerkt — und lassen sich in den normalen Entwicklungszyklus einplanen statt als ungeplante Feuerwehreinsätze abzuarbeiten.
Modell-Updates durch Drittanbieter verlieren ihren Schrecken. Wer eine Eval-Suite hat, läuft sie nach jedem externen Update und weiß innerhalb von Stunden, ob sich das Systemverhalten verändert hat. Ohne Evals ist ein Anbieter-Update ein Risiko. Mit Evals ist es ein kontrollierbares Ereignis.
Systematische Evals schonen Ihre Experten-Ressourcen und beschleunigen den Go-live. Ein proaktives Verständnis der Systemdynamik verkürzt die Zeitspanne von der Entwicklung bis zur Marktreife (Time-to-Market) massiv.
Die interne Diskussion verändert sich ebenfalls. Statt „das System verhält sich manchmal komisch“ gibt es konkrete Zahlen: Retrieval-Qualität auf Testfragenset X, Halluzinationsrate in Kategorie Y, Token-Verbrauch pro Anfrage Z. Das verschiebt Gespräche mit Stakeholdern von Bauchgefühl zu Steuerungsinformation. Für die Geschäftsführung bedeutet dieses Bewusstsein den entscheidenden Vorsprung: Es geht darum, die Effizienzsteigerung in Unternehmen durch KI nicht dem Zufall zu überlassen, sondern sie durch professionelles Engineering steuerbar zu machen.
RAG + AI-Evals erhöhren Transparenz und Qualität
SMADEV unterstützt Sie dabei, diese technologischen Herausforderungen nicht als Barrieren, sondern als exklusive Chance zur Wertschöpfung zu nutzen. Indem wir die Dynamik von RAG-Systemen als beherrschbare Prozesskette definieren, legen wir den Grundstein für eine KI-Lösung, die nicht nur technisch überzeugt, sondern einen harten und messbaren ROI liefert.
Welchen Kerngedankekn Sie übernehmen sollten:
Wer seine RAG-Pipeline versteht, senkt Entwicklungskosten und vermeidet teure Überraschungen im Betrieb. Unternehmen, die Retrieval-Qualität und Token-Verbrauch aktiv messen, steuern ihre KI-Investition, alle anderen verwalten sie.
Erfahren Sie mehr über unsere Methodik:
Unser AI-Evals-Ansatz übersetzt komplexe Datenarchitekturen systematisch in wertschöpfende, steuerbare KI-Produkte.
Lassen Sie uns den nächsten Schritt gemeinsam gehen.
Steht Ihr RAG-System vor dem Go-live oder läuft es bereits und Sie fragen sich, ob die Qualitätssicherung hält was sie verspricht?
Das Problem liegt meist nicht im Sprachmodell, sondern davor. Falsches Chunking zerschneidet relevante Informationen so, dass kein einzelnes Fragment die Antwort vollständig enthält. Fehlende Metadaten verhindern gezieltes Filtern. Veraltete Dokumente ohne Versionierung liefern korrekt klingende, aber längst überholte Antworten. Das Modell halluziniert nicht, es arbeitet mit dem, was das Retrieval ihm gibt.
Die häufigsten: schlechte Datenqualität im Quelldokument (Duplikate, Widersprüche, veraltete Inhalte), falsches Chunking (zu groß oder zu klein), fehlende oder inkonsistente Metadaten, ein Systemprompt der mit abgerufenen Fragmenten kollidiert, sowie Index-Updates ohne anschließende Retrieval-Tests. Jede Fehlerquelle erzeugt andere Symptome und braucht eigene Testabdeckung.
Die Fehlerquellen in einer „Black-Box RAG“ sind vielfältig und oft unsichtbar (Silent Failures):
Ja, bei stabilem Index, stabilem Embedding-Modell und stabilen Parametern ist Retrieval reproduzierbar. Andere Ergebnisse bei gleicher Frage entstehen nur nach einem Index-Update oder Modell-Wechsel. Deshalb sind Index-Updates die kritischen Ereignisse, nach denen Retrieval-Tests erneut laufen müssen. Die nicht-deterministische Komponente im System ist ausschließlich das LLM.
Bestehende Vektoren behalten ihre Position im Vektorraum. Neue Dokumente erweitern den Suchraum, sie verschieben nichts. Was sich ändert: Bei bestimmten Abfragen können neu hinzugefügte Dokumente jetzt relevanter erscheinen als bisher abgerufene Fragmente. Das kann gewollt sein oder ein Problem, wenn veraltete Inhalte nicht entfernt wurden.
Hier wird nach Dimensionen unterschieden. Je nach Use Case sind diese unterschiedlich gewichtet, dabei ist nicht jede Dimension immer gleich relevant. Zu ihnen gehört: Antwort & Outcome, Grounding & Wissen, Agent & Tooling, Conversation und Operational Quality.
Spätestens bevor ein RAG-System in Produktion geht. Ohne Evals merkt man Qualitätsverluste erst, wenn Nutzer sie melden, zu dem Zeitpunkt hat das System bereits Vertrauen verbraucht.
Die Kosten: erneute Entwicklungszyklen, ungeplante Hotfixes, und im schlimmsten Fall ein System das intern als unzuverlässig gilt und nicht genutzt wird. Ein Testfragenset mit 50 bis 100 Fragen und definierten Referenzantworten ist der minimale Einstieg und lässt sich in einem Sprint aufbauen.
Erfolgsfaktoren für KI-Projekte 2026: Experten-Insights gegen den Stillstand in der Praxis
Wie erzielen Unternehmen 2026 einen positiven ROI mit ihren KI-Projekten?
KI ist in vielen Unternehmen angekommen. Was oft fehlt, ist die Wirkung. Zwischen „wir nutzen KI“ und „unsere KI- Projekte liefern messbare Ergebnisse“ liegt eine Lücke, die 2026 für viele zum entscheidenden Faktor wird.
In unserer täglichen Arbeit sehen wir sehr unterschiedliche Ausgangslagen: Unternehmen, die viel in KI investieren und dennoch keinen klaren Nutzen sehen, während andere mit kleinen Projekten echten Fortschritt und positiven ROI erzielen. Der Unterschied liegt selten in der Technologie selbst. Er entsteht durch Klarheit in der Vorbereitung, Datenqualität und Umsetzung der KI-Projekte.
Für diesen Artikel haben wir mehrere Mitglieder der Produktteams von SMADEV und aus unserem Innovativen Lab EpicInsights gebeten, je einen zentralen Punkt zu teilen, der aus ihrer Projekterfahrung heraus den größten Unterschied macht. Keine abstrakten KI-Trends, sondern konkrete Beobachtungen aus realen Kundenprojekten.
Nach dem Lesen können Sie besser beurteilen
warum bestehende KI-Projekte nicht die gewünschte Wirkung entfalten
welche Entscheidungen den größten Hebel haben
und wo Sie ansetzen sollten, bevor Sie weiter investieren.
Michael Mörs – „KI ist nur so gut wie Ihre Datengrundlage“
Geschäftsführer SMADEV & Epicinsights
Wenn Unternehmen über KI sprechen, geht es sehr schnell um Modelle, Cloud-Tools und neue Möglichkeiten. Was dabei fast immer zu spät kommt, ist der Blick auf die eigenen Daten und Prozesse.
Aus meiner Erfahrung ist genau das der Punkt, an dem sich entscheidet, ob ein KI-Projekt später skaliert, oder teuer scheitert (Hier mehr erfahren). Denn KI arbeitet nicht mit Visionen, sondern mit dem, was Sie ihr geben. Und das sind Daten, eingebettet in Prozesse. KI-Projekte sind zunächst keine IT-Projekte, sondern Business Development-Aufgaben.
Viele Unternehmen starten KI-Initiativen, ohne diese Grundlage ernsthaft zu prüfen. Daten liegen verstreut, sind historisch gewachsen, uneinheitlich gepflegt oder nicht klar mit einem Ziel verknüpft. Für klassische IT und Reportings reicht das oft noch aus. Für KI reicht es nicht. Jede Unklarheit in den Daten wirkt sich direkt auf die Qualität der Ergebnisse aus. Und jeder Tag, an dem diese Themen ignoriert werden, erhöht die späteren Kosten: in der Projekt-Vorbereitung, im Training, im Rollout und in der Nacharbeit.
Diese Arbeit lässt sich nicht überspringen. Was heute nicht sauber aufgebaut wird, muss später unter Zeitdruck und mit deutlich höherem Aufwand korrigiert werden. In Machine-Learning-Projekten zeigt sich das sehr konkret: schlechtere Trainingsqualität, schwächere Modelle und falsche Erwartungen an den Output. Was wie ein technisches Problem seitens der KI-Modelle wirkt, ist in Wahrheit ein strukturelles.
Dahinter steckt ein grundlegender Denkfehler: Daten werden als Kostenblock betrachtet, nicht als Werttreiber. Für KI funktioniert dieses Denken nicht. Wer nicht bereit ist, Zeit, Ressourcen und Aufmerksamkeit in Daten und Prozesse zu investieren, wird KI nie zuverlässig nutzen können.
Mein Tipp lautet deshalb klar: Beschäftigen Sie sich früh und konsequent mit Ihren Daten und Prozessen. Nicht erst beim KI-Tool-Setup, dem Rollout oder bei der Skalierung, sondern jetzt. Jeder aufgeschobene Tag verschiebt das Problem und verteuert es.
Marc Böhm – „Erfolgreiche KI-Projekte benötigen Klarheit“
Teamleitung Product & Design
Weil KI-Tools heute extrem schnell Ergebnisse liefern, entsteht leicht der Eindruck, man könne sich die Vorarbeit sparen. Eine Idee reicht, ein Tool ist gefunden, ein erster Prototyp steht nach wenigen Stunden oder Tagen. Technisch funktioniert das meist auch. Inhaltlich verfehlt es jedoch häufig das Ziel.
Aus meiner Projekterfahrung scheitern viele Lösungen nicht daran, dass sie schlecht gebaut sind, sondern daran, dass sie am eigentlichen Bedarf vorbeigehen. Unternehmen nehmen sich zu wenig Zeit, im Vorfeld sauber zu analysieren, was sie wirklich erreichen wollen. Welche Zielgruppe soll angesprochen werden? Welches konkrete Problem soll gelöst werden? Und woran würden Sie später erkennen, dass das Projekt erfolgreich war? Ohne diese Klarheit wird KI zur schnellen Antwort auf eine schlecht gestellte Frage.
Gerade im B2B- wie auch im B2C-Kontext zeigt sich das sehr deutlich. Ideen lassen sich heute leicht kopieren, Funktionen sind austauschbar. Der Unterschied entsteht nicht mehr durch das „Was“, sondern durch das „Für wen“ und „Warum“. Wer diese Fragen nicht sauber beantwortet, baut Lösungen, die zwar existieren, aber nicht genutzt werden.
Mein Tipp: Investieren Sie vor jedem KI-Projekt bewusst Zeit in Analyse und Zielklarheit. Mit einer strukturierten Vorarbeit wird KI gezielt eingesetzt, zahlt auf konkrete Ziele ein und entfaltet tatsächliche Wirkung – statt nur schnell umgesetzt zu sein.
Dr. Kevin Lamkiewicz – „Ohne Ownership bleibt KI ein teures Experiment“
Teamleitung Data Science
Viele KI-Projekte starten mit großer Euphorie. Es gibt Budget, es gibt Ideen, es gibt schnelle Ergebnisse. Genau hier liegt das Problem: Der Einstieg ist leicht, aber der laufende Betrieb ist oft mehr Arbeit als gedacht wird.
Was ich immer wieder sehe, ist kein technisches Scheitern, sondern ein organisatorisches. Niemand fühlt sich wirklich verantwortlich. Das Projekt ist „da“, läuft irgendwie, verursacht Kosten, aber keiner sorgt dafür, dass es genutzt, gepflegt und weiterentwickelt wird. Ohne klare Zuständigkeit bleibt KI ein nettes Experiment.
Eine Person muss den Hut aufhaben und sagen: Das ist mein Thema. Diese Verantwortung endet nicht nach dem Go-live, sondern beginnt dort erst richtig. Es geht darum, Nutzung sicherzustellen, Wirkung zu überprüfen und Anpassungen vorzunehmen, wenn das KI-System mit der täglichen Arbeitswelt konfrontiert wird oder sich Daten oder Ziele ändern. Mit Ownership wird aus einem Prototyp ein verlässlicher Teil Ihres Unternehmens. Ohne Ownership bleibt es ein System, das gut aussieht, aber keinen echten Beitrag leistet.
Mein wichtigster Tipp lautet deshalb: Klären Sie Ownership von Anfang an.
Matthias Hauert – „Startet bei der Kommunikation“
Chief Technology Officer
Wenn KI-Projekte scheitern, suchen viele den Fehler zuerst in der Technik. Falsches Tool, falsches Modell, falsche Architektur. Aus meiner Erfahrung ist das fast immer die falsche Spur. Die Technik funktioniert in der Regel erstaunlich gut. Was nicht funktioniert, ist die Kommunikation zwischen den Menschen, die sie einsetzen sollen.
Mit KI wird dieses Problem sogar größer, weil plötzlich alles „richtig“ klingt. Mails sind sauber formuliert, Konzepte wirken logisch, Abstimmungen fühlen sich effizient an. Und genau das ist gefährlich. KI stimmt fast immer zu, widerspricht selten und hört nicht wirklich zu. So entstehen Projekte, in denen alle glauben, sie seien auf derselben Seite, während in Wahrheit jeder etwas anderes im Kopf hat.
Sprechen Sie daher miteinander, auch über Unsicherheiten und offene Fragen. Nutzen Sie KI, um Dinge zu strukturieren oder Informationen sichtbar zu machen, aber überlassen Sie ihr nicht die Führung. Wenn Sie diesen Schritt überspringen, bauen Sie Systeme, die reibungslos laufen und trotzdem am Ziel vorbeigehen. Wenn Sie ihn ernst nehmen, wird KI zum Verstärker guter Entscheidungen statt zum Beschleuniger von Missverständnissen.
Mein Tipp ist deshalb bewusst menschlich: Bevor Sie automatisieren, klären Sie zuerst, was wirklich gebraucht wird.
Florian Zeidler – „KI braucht Qualitätsmessung“
Data Scientist / AI Engineer
Gerade weil KI-Systeme heute so leicht zu bauen sind, wird ein entscheidender Punkt oft übersehen: Qualität. Viele Unternehmen setzen Chatbots oder automatisierte Prozesse ein und verlassen sich auf den ersten guten Eindruck.
Solange sich nichts ändert, funktioniert das auch. Doch KI-Systeme reagieren sensibel auf Veränderungen:
neue Daten,
andere Modelle,
angepasste Regeln
verschiedene Tonalitäten und Prompts.
Ohne Kontrolle merken Sie erst spät, dass die Qualität kippt.
Mein Tipp ist daher, Qualität messbar zu machen und regelmäßig zu überprüfen.
Statt die KI einfach laufen zu lassen, sollten Sie systematisch testen, wie Ihr KI-System in unterschiedlichen Situationen reagiert. Dazu gehören auch simulierte Nutzer und schwierige Fälle, bei denen das System idealerweise ehrlich sagt, dass es keine Antwort hat. Wenn Sie diese Evaluierungen fest in Ihre Prozesse integrieren, erkennen Sie Probleme frühzeitig. Ohne diesen Schritt setzen Sie KI blind ein und hoffen, dass alles gutgeht. Mit ihm steuern Sie bewusst, wie zuverlässig und sicher Ihr System wirklich ist.
KI-Implementierung 2026: Unser Fazit für Entscheider
Die Muster sind klar erkennbar: Erfolgreiche KI-Projekte beginnen nicht mit Technologie, sondern mit strategischer Vorarbeit, gepflegter Datenbasis und konstantem Monitoring, Kommunikation und Projektverantwortlichkeit.
Unternehmen, die das früh verinnerlichen, verschaffen sich keinen kurzfristigen Vorsprung, sondern eine strukturelle Stärke.
Wenn Sie sich in den beschriebenen Mustern wiedererkennen, lohnt es sich, einen Schritt zurückzugehen um danach gezielter vorzugehen. In Gesprächen mit Unternehmen unterstützen wir genau dabei: Klarheit schaffen, priorisieren und fundierte Entscheidungen vorbereiten.
Wenn Sie diese Fragen vertiefen möchten, sprechen Sie uns an:
KI in Unternehmen: Generiert Ihr Data-Science-Team bereits echten Business-Value?
Wie erzielt man eine reale Effizienzsteigerung durch KI?
Während marktführende Unternehmen durch den Einsatz von Big Data und KI signifikante Wettbewerbsvorteile realisieren und ihre Margen sichern, stagnieren viele interne Daten-Abteilungen in der Rolle eines reaktiven Service-Dienstleisters. Das Backlog ist gefüllt, die Auslastung ist hoch, doch der messbare Beitrag zum Unternehmenserfolg bleibt oft hinter den Erwartungen zurück.
In diesem Beitrag „Wie generiert ein Data-Science-Team echten Business-Value?“ erfahren Sie, warum das klassische „Ticket-Abarbeitungs-Modell“ die Innovationskraft Ihrer Organisation hemmt. Sie lernen drei strategische Hebel kennen, mit denen Sie Ihr Data-Science-Team neu positionieren, um die Lücke zwischen technischem Output und ökonomischem Outcome zu schließen und eine reale Effizienzsteigerung durch KI zu erzielen.
Die Illusion der Produktivität: Wenn Output nicht gleich Outcome ist
Ein häufiges Phänomen in der Unternehmenspraxis ist die Diskrepanz zwischen wahrgenommener Geschäftigkeit und tatsächlicher Wertschöpfung. Hochqualifizierte Data-Engineers und Analysten werden faktisch zu „Report-Lieferanten“ degradiert, deren Primäraufgabe darin besteht, Ad-hoc-Anfragen aus Marketing, Sales oder Management zu bedienen.
Das Resultat ist eine „Illusion von Produktivität“: Tickets werden geschlossen und Dashboards werden publiziert. Doch wenn wir analysieren, wie man moderne IT-Teams führen sollte, wird schnell klar: Wir verwechseln hier Output (Menge der gelieferten Artefakte) mit Outcome (Qualität der getroffenen Entscheidungen).
Wenn die Beantwortung einer simplen Businessfrage Wochen dauert, liegt die Ursache selten in der technologischen Kompetenz der Mitarbeiter. Es handelt sich um ein strukturelles Defizit im Operating Model. Um KI-Projekte erfolgreich zu skalieren, bedarf es einer Abkehr von der reinen Service-Mentalität.
Hebel 1: Transformation vom „Ticket-System“ zum Daten-Produkt
Die Verwaltung von Daten-Initiativen über klassische IT-Ticket-Systeme ist für strategische Fragestellungen ungeeignet. Ein Ticket-System fördert eine reaktive Haltung: Eine Anforderung kommt herein, wird isoliert bearbeitet und „über den Zaun“ zurückgeworfen.
Für erfolgreiche KI-Projekte ist jedoch der geschäftliche Kontext essenziell. Wenn Data Engineers die strategischen Ziele hinter einer Anforderung nicht verstehen, entwickeln sie Lösungen, die technisch funktionieren, aber am Business-Need vorbeigehen.
Die Lösung: Etablieren Sie ein Produkt-Mindset. Definieren Sie klare „Data Products“ mit dedizierten Ownern. Das Team arbeitet nicht mehr Tickets ab, sondern entwickelt proaktiv Lösungen für spezifische Business-Probleme.
Hebel 2: KPIs neu denken – Time-to-Decision statt Dashboard-Quantität
Es ist eine unbequeme Wahrheit im Bereich Big Data und KI: Ein Großteil der erstellten Dashboards (Studien sprechen von bis zu 80 %), wird wenige Wochen nach dem Rollout nicht mehr konsultiert. Diese „Datenfriedhöfe“ binden wertvolle Wartungsressourcen und verhindern Innovation.
Führungskräfte müssen aufhören, die reine Anzahl an Reports als Erfolgsindikator zu werten. Die entscheidende Metrik für eine Effizienzsteigerung durch KI lautet „Time-to-Decision“.
Wie stark verkürzt das Datenprodukt den Zeitraum von der Fragestellung bis zur fundierten Entscheidung?
Wird Komplexität reduziert oder durch zusätzliche Metriken nur erhöht?
Die größte Barriere, wenn es darum geht, IT-Teams zu führen und in die Wertschöpfung zu integrieren, ist das Silo-Denken. Solange Data Analysts isoliert in der IT-Abteilung sitzen, fehlt ihnen das tiefgreifende Verständnis für die operativen Herausforderungen der Fachbereiche.
Die Antwort liegt in der cross-funktionalen Integration. Analysten sollten temporär oder dauerhaft in die Business-Units (z. B. Sales oder Marketing) integriert werden („Embedded Analysts“). Nur durch diese organisatorische Nähe entsteht das notwendige Domänenwissen, um Data Science Team-Ressourcen so einzusetzen, dass sie echte Schmerzpunkte adressieren.
Jetzt Whitepaper Downloaden
Was erfolgreiche KI-Projekte ausmacht und warum andere scheitern!
Warum Technologie selten das Problem ist und wo KI-Projekte wirklich scheitern.
Ein 6-Schritte-Plan für erfolgreiche, praxisnahe KI-Umsetzung.
Wie Menschen, nicht Algorithmen über den Erfolg entscheiden.
Wie generiert ein Data-Science-Team echten Business-Value? Die Transformation hin zu einer datengetriebenen Organisation erfordert mehr als nur technologische Investitionen. Wir müssen uns von der Vorstellung des „Data-Service-Desks“ lösen und das Data-Team als strategischen Partner auf Augenhöhe etablieren. Wahre Geschwindigkeit entsteht nicht durch operativen Druck, sondern durch strategische Klarheit und den Fokus auf werttreibende Initiativen.
Wollen Sie das volle Potenzial Ihrer Daten heben?
Befindet sich Ihr Team noch im „Reaktions-Modus“ oder treiben Sie bereits aktiv Innovationen voran? Wenn Sie erfahren möchten, wie Sie Ihre Datenstrategie neu ausrichten und Ihr Operating Model für messbaren Business-Impact optimieren können, lassen Sie uns sprechen.
Vereinbaren Sie jetzt ein unverbindliches Strategiegespräch, in dem wir analysieren, wie wir auch in Ihrer Organisation die Transformation vom Cost-Center zum Wertschöpfer realisieren.
Startschuss 2026: Neue Netzwerke, neue Horizonte – SMADEV mit voller Kraft voraus
Das Jahr 2026 ist noch jung, doch bei der SMA Development GmbH (SMADEV) sind die Weichen bereits voll auf Zukunft gestellt. Wir starten mit einer klaren Mission in dieses Jahr: Wir wollen Innovationen nicht nur im stillen Kämmerlein entwickeln, sondern sie aktiv im Ökosystem vorantreiben. Denn wir sind überzeugt: Echte Effizienzsteigerung in Unternehmen und technologischer Fortschritt entsteht selten in Isolation, sondern am besten durch Synergien, Austausch und starke Partnerschaften. Die neuen SMADEV Netzwerke 2026 stehen für Innovation durch starke Partnerschaften.
Deshalb freuen wir uns riesig, pünktlich zum Jahresbeginn unsere Mitgliedschaft in gleich drei hochkarätigen Netzwerken bekannt zu geben. Diese Schritte sind bewusst gewählt, um unsere Expertise dort einzubringen, wo sie den größten Impact hat: lokal, national und in spezialisierten Forschungsfeldern. Erfahre, wer hinter diesen Partnern steckt und was sie besonders macht.
1. Jena Digital: Stärkung des Heimatstandorts
Als Unternehmen mit Wurzeln in Jena liegt uns die lokale Entwicklung besonders am Herzen. Mit unserem Beitritt zu Jena Digital werden wir Teil des Digital Hubs unserer Region. Unser Ziel ist es, den IT-Standort Jena weiter zu stärken und uns eng mit der hiesigen Wissenschaft und Wirtschaft zu vernetzen. Gemeinsam wollen wir die digitale Transformation direkt vor unserer Haustür gestalten und Jena als Leuchtturm für digitale Innovationen sichtbar machen.
Jena Digital e.V. stärkt den IT-Standort durch:
Vernetzung: Verbindung von Wirtschaft, Wissenschaft und Start-ups.
Wissenstransfer: Organisation von Fach-Events und Konferenzen.
Talentförderung: Initiativen für digitale Bildung und Fachkräftegewinnung.
Innovation: Fokus auf KI, Smart City und Digital Health.
2. KI Bundesverband: Verantwortungsvolle KI für Deutschland
Künstliche Intelligenz ist die Schlüsseltechnologie unserer Zeit. Durch unsere Mitgliedschaft im KI Bundesverband, dem größten KI-Netzwerk Deutschlands, setzen wir ein klares Zeichen. Wir engagieren uns für die digitale Souveränität und den ethischen Einsatz von KI. Es geht uns darum, Deutschland als KI-Leitmarkt zu festigen. Wir bringen unsere technische Expertise ein, um sicherzustellen, dass KI-Lösungen nicht nur leistungsfähig, sondern auch vertrauenswürdig und zukunftssicher sind. Der Verband selbst vertritt die Interessen der KI-Community gegenüber der Politik und setzt sich aktiv für eine starke Förderung von KI-Technologienein.
3. InfectoGnostics Forschungscampus Jena: Wo Tech auf Gesundheit trifft
Besonders spannend ist die Brücke, die wir mit dem InfectoGnostics Forschungscampus Jena schlagen. In dieser starken öffentlich-privaten Partnerschaft verschmelzen Technologie und Gesundheit. Unser Fokus liegt darauf, mit digitalen Lösungen Innovationen in der Diagnostik zu beschleunigen, für die Medizin der Zukunft. Wenn moderne Diagnostik auf High-End Data Science und KI trifft, entsteht ein enormes Potenzial, um echte Probleme im Gesundheitswesen zu lösen.
Ein Fest für unser Innovations-Lab „epicinsights“
Was bedeuten diese neuen Partnerschaften konkret für unsere tägliche Arbeit? Für epicinsights, das InnovationsLab der SMA Development GmbH, ist dieser Schritt ein echter Meilenstein.
Die neuen Netzwerke bedeuten vor allem eines: Mehr Sichtbarkeit und einen kontinuierlichen, tiefgehenden Austausch mit Forschenden, KI-Praktikern und anderen Unternehmen. Genau dieser Input von außen ist der Treibstoff, der unsere Projekte besser, relevanter und innovativer macht.
Auf ein erfolgreiches Jahr 2026!
Wir freuen uns auf den inspirierenden Austausch, spannende gemeinsame Projekte und darauf, mit diesen starken Partnern: Jena Digital, dem KI Bundesverband und InfectoGnostics, noch mehr zu bewirken.
Die Segel sind gesetzt. Auf neue Horizonte! 🌟
KI im Projektmanagement: Darum entscheidet der „Faktor Mensch“ über den Erfolg
Warum scheitern KI-Projekte? (Teil 3)
Technologie ist skalierbar, Vertrauen nicht. Im modernen KI-Projektmanagement scheitern Initiativen selten am Code, sondern an der Kultur. Neben der Datenstrategie ist Change Management der kritische Pfad. Ohne die aktive Einbindung der Stakeholder wird aus einer KI-Implementierung schnell ein teures Missverständnis. Wir zeigen, wie Sie KI-Projekte so steuern, dass Ihr Team mitzieht.
Der Wandel im KI-Projektmanagement: Von Skepsis zu Shadow AI
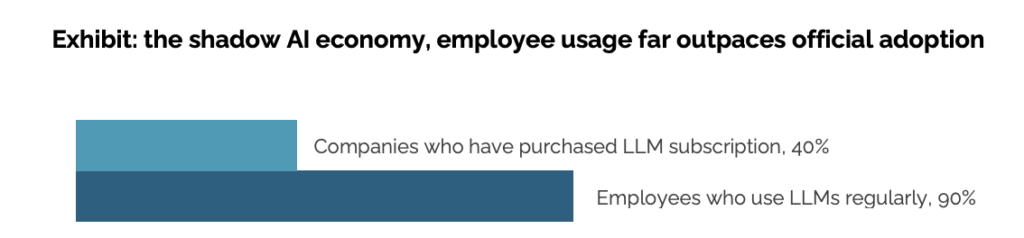
Noch vor wenigen Jahren war Künstliche Intelligenz in Unternehmen ein technisches Randthema. Data Scientists arbeiteten in geschlossenen Teams, während Fachabteilungen skeptisch auf „die Maschine“ blickten, die nun ihre Prozesse automatisieren sollte. Doch die Zeiten haben sich radikal verändert. Seit 2023, befeuert durch ChatGPT, Copilot & Co., hat sich die Wahrnehmung um 180 Grad gedreht. Skepsis wurde zu Neugier, Distanz zu Eigeninitiative. Plötzlich experimentieren Mitarbeitende selbst mit GenAI-Tools, prompten Modelle, bauen Automatisierungen und das oft, ohne dass die IT es überhaupt merkt.
Shadow AI im Projektmanagement: Risiko oder Chance?
Eine aktuelle Studie des MIT („The GenAI Divide“, 2025) bestätigt diesen Wandel: 90 % der Mitarbeitenden in Unternehmen, deren KI-Projekte offiziell gescheitert sind, nutzen privat oder beruflich trotzdem KI, häufig über eigene, selbst bezahlte Accounts. Sogenannte Shadow AI. Was nach einem Albtraum für IT-Security und Compliance klingt, offenbart zugleich eine entscheidende Wahrheit:
Menschen wollen mit KI arbeiten, sie tun es nur oft nicht in den Systemen, die Sie ihnen geben.
Wir nutzen Cookies auf unserer Website. Einige von ihnen sind essenziell, während andere uns helfen, diese Website und Ihre Erfahrung zu verbessern. Indem Sie auf "Alle akzeptieren" klicken, stimmen Sie der Verwendung von Cookies zu und willigen gem. Art. 49 Abs 1 S. 1 lit. a DSGVO ein, dass Ihre Daten in den USA verarbeitet werden, wo US-Behörden möglicherweise auf diese anonymisierten Informationen zugreifen. Wenn Sie auf "Speichern" klicken, findet die vorgehend beschriebene Übermittlung nicht statt. Wenn Sie unter 16 Jahre alt sind und Ihre Zustimmung zu freiwilligen Diensten geben möchten, müssen Sie Ihre Erziehungsberechtigten um Erlaubnis bitten. Wir verwenden Cookies und andere Technologien auf unserer Website. Einige von ihnen sind essenziell, während andere uns helfen, diese Website und Ihre Erfahrung zu verbessern. Personenbezogene Daten können verarbeitet werden (z. B. IP-Adressen), z. B. für personalisierte Anzeigen und Inhalte oder Anzeigen- und Inhaltsmessung. Weitere Informationen über die Verwendung Ihrer Daten finden Sie in unserer Datenschutzerklärung.
Funktional
Immer aktiv
Die technische Speicherung oder der Zugang ist unbedingt erforderlich für den rechtmäßigen Zweck, die Nutzung eines bestimmten Dienstes zu ermöglichen, der vom Teilnehmer oder Nutzer ausdrücklich gewünscht wird, oder für den alleinigen Zweck, die Übertragung einer Nachricht über ein elektronisches Kommunikationsnetz durchzuführen.
Vorlieben
Die technische Speicherung oder der Zugriff ist für den rechtmäßigen Zweck der Speicherung von Präferenzen erforderlich, die nicht vom Abonnenten oder Benutzer angefordert werden.
Statistiken
The technical storage or access that is used exclusively for statistical purposes.Die technische Speicherung oder der Zugriff, der ausschließlich zu anonymen statistischen Zwecken verwendet wird. Ohne eine Vorladung, die freiwillige Zustimmung Ihres Internetdienstanbieters oder zusätzliche Aufzeichnungen von Dritten können die zu diesem Zweck gespeicherten oder abgerufenen Informationen allein in der Regel nicht zu Ihrer Identifizierung verwendet werden.
Marketing
Die technische Speicherung oder der Zugriff ist erforderlich, um Nutzerprofile zu erstellen, um Werbung zu versenden oder um den Nutzer auf einer Website oder über mehrere Websites hinweg zu ähnlichen Marketingzwecken zu verfolgen.